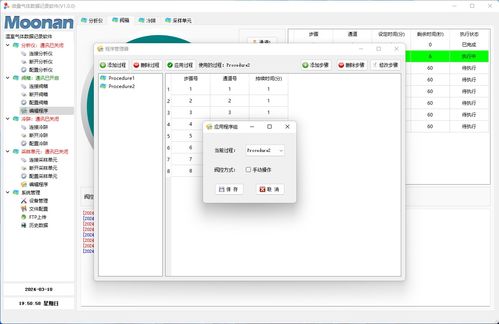
微量氣體分析在環境監測、工業生產、科學研究等領域具有廣泛應用,實時、準確地記錄氣體數據至關重要。本文介紹一款基于Qt框架開發的微量氣體數據記錄軟件,該軟件旨在提供一個穩定、高效、用戶友好的數據采集與管理平臺。
一、 軟件概述與設計目標
本軟件的核心功能是連接并控制微量氣體分析儀(如氣相色譜儀、質譜儀或特定氣體傳感器),實時讀取測量數據,并將數據以結構化的形式記錄、存儲、顯示與分析。其主要設計目標包括:
- 跨平臺兼容性:利用Qt的跨平臺特性,確保軟件能在Windows、Linux、macOS等主流操作系統上穩定運行。
- 實時性與穩定性:實現可靠的數據通信,保證在高頻率數據采集下的實時響應與系統穩定。
- 數據完整性:確保采集的數據被準確、完整地記錄,并提供防丟失機制。
- 用戶友好性:提供直觀的圖形界面,便于用戶配置參數、監控實時數據、查看歷史記錄及進行基本分析。
- 可擴展性:軟件架構支持后續添加新的儀器驅動、數據分析模塊或報告生成功能。
二、 系統架構與關鍵技術
軟件采用典型的模塊化設計,主要分為以下幾個核心模塊:
- 通信與設備驅動模塊:
- 負責與硬件設備進行通信。根據儀器提供的接口(常見的有RS-232/485串口、TCP/IP網絡、USB或GPIB等),使用Qt的
QSerialPort、QTcpSocket等類實現通信層。
- 該模塊解析儀器特定的通信協議,將指令封裝下發,并接收、解析儀器返回的數據包,提取出有效的濃度、流量、溫度等測量值。
- 數據管理模塊:
- 這是軟件的核心。負責處理解析后的實時數據流。
- 實時處理:對數據進行校驗、濾波(如滑動平均)等初步處理。
- 存儲:使用輕量級數據庫(如SQLite,Qt內置支持
QSqlDatabase)或直接寫入CSV、TXT文件。數據庫存儲便于進行復雜查詢和歷史數據追溯,文件存儲則簡單通用。通常采用“數據庫主存+文件備份”的雙重策略確保數據安全。
- 該模塊定義統一的數據結構,供其他模塊調用。
- 用戶界面模塊:
- 基于Qt Widgets或QML構建。主界面通常包含:
- 設備連接與參數配置區:設置通信端口、波特率、采樣周期等。
- 實時數據展示區:以數字、儀表盤、實時曲線圖(使用
QChart或第三方庫如QCustomPlot)等形式動態顯示當前各氣體成分的濃度。
- 數據記錄控制區:開始/停止記錄、選擇存儲路徑和文件格式。
- 歷史數據瀏覽與分析區:提供表格和曲線形式的歷史數據查詢,支持按時間范圍篩選,并可進行簡單的統計(如平均值、最大值、最小值)和導出。
- 系統狀態欄:顯示連接狀態、記錄狀態、錯誤信息等。
- 任務調度與邏輯控制模塊:
- 作為軟件的中樞,協調各模塊工作。例如,定時觸發數據采集指令、通知界面更新、管理數據存儲隊列等。Qt的信號與槽機制在此發揮了巨大作用,實現了模塊間的低耦合通信。
三、 實現特點與優勢
- 利用Qt框架優勢:
- 信號與槽:簡化了實時數據從通信層到UI層、存儲層的傳遞流程,使代碼清晰、易于維護。
- 多線程:通過
QThread將耗時的數據通信和存儲操作放在子線程中,避免阻塞主UI線程,保證界面的流暢性。
- 豐富的UI控件與繪圖支持:快速構建專業且美觀的操作界面。
- 靈活的數據處理:軟件可內置常見的數據處理算法,用戶可根據需要選擇是否啟用濾波或進行單位換算。
- 健壯的錯誤處理:對設備斷線、通信超時、存儲空間不足等異常情況進行捕獲和處理,給出明確的用戶提示,并盡可能保持系統穩定或安全關閉記錄任務。
- 配置化管理:使用INI或XML文件存儲軟件的常用配置(如最近使用的端口、默認存儲路徑、圖表顏色方案等),提升用戶體驗。
四、 應用場景與展望
該軟件可廣泛應用于:
- 實驗室研究:長時間監測化學反應過程中的氣體產物或消耗。
- 環境空氣監測:定點或移動監測大氣中的溫室氣體、污染物(如SO?, NOx, VOCs)濃度。
- 工業過程控制:監測生產線或密閉空間中的特定氣體濃度,用于安全預警或工藝優化。
- 能源領域:如天然氣成分分析、沼氣發酵過程監控等。
軟件可進一步擴展以下功能:
- 支持更多型號的儀器,構建通用的驅動管理框架。
- 集成更強大的數據分析工具,如趨勢分析、相關性分析、自動報告生成(PDF/Word)。
- 添加網絡功能,實現數據的遠程傳輸與多終端監控(結合Qt Network模塊)。
- 實現數據觸發報警功能,當濃度超過設定閾值時,通過界面、聲音或網絡消息通知用戶。
基于Qt開發的微量氣體數據記錄軟件,憑借其跨平臺能力、高效的開發效率和強大的功能集成潛力,能夠為各行業的氣體監測需求提供一個可靠、靈活的軟件解決方案。其模塊化設計也確保了軟件能夠隨著需求的變化而不斷進化與完善。